汇编语言的学习
汇编语言
算数平移和逻辑平移
关于这个平移问题,分为算术左右移和逻辑左右移
算术左移和逻辑左移:
只要数字向左移动一位就好了,然后右边补0,其他都不用管
算术右移和逻辑右移:
逻辑右移是很正常的,也就是只要向右移动,补补0就好了
而算术右移就不一样!
只有算术右移,是让符号位一起走
- 向右移动,并且补的是和符号位是一样的
也就是说要不是全补0要不是全补1
IEEE浮点数编码
首先你要知道怎么是一个小数的十进制变二进制
但我觉得我已经知道了我就不讲了
32位编码格式
对于一个32位的浮点数,它的编码格式
在32位二进制串中,阶码部分用8位来存储,尾数部分用23位来存储,还有1位是符号位。
讲起来有点麻烦我直接上例子
例:12.25按照32位IEEE编码
- 符号位
12.25变成二进制:1100.01
因为是正数,符号位是0
- 阶码
阶码部分是这样的:
因为是1100.01,按照规则这是
$$
1.10001*2^3
$$
所以我们知道阶码数是127+3=130 (这是规定我也不知道为什么是这样)
130再变为二进制为:10000011
阶码也是8位,这个就是阶码
- 尾数部分
尾数是我们之前的
$$
1.10001*2^3
$$
中的小数点后面的部分:10001
又因为是 23位的尾数部分
所以是10001000000000000000000(共23位)
所以这个数是
0 10000011 10001000000000000000000
32位编码格式
64位的阶码是+1023
64位的编码部分是
1 11 52
关于一个字节为什么是 -128到127
补码的好处:
首先加入没有补码,+0 在计算机中的表示0 000 0000. -0 在计算机中的表示1 000 0000. 并不一致。
如果采用补码-0 的补码就是 0 000 0000. 两者一致
其次我们知道8位二进制的表示形式总共有0000 0000-1111 1111 那么多,恰好是2^8=256. 也就是说理论上可以表示256个十进制数字。我们前面知道,-0 在计算机中如果再用原码 就是1 000 0000 。如果采用反码就是1 111 1111. 会多占用一个表达。
所以如果采用补码就可以把1 000 0000 这个表达空出来表示一个十进制数字。 很显然用它来表示-128 最为合理。
还可以从另外一个角度来理解: -127 的补码是1000 0001.再减去1 就是1000 0000 。那-127-1=-128.
所以补码的好处就是计算机的表达位数可以充分利用表示跟多的十进制数。
关于汇编指令
寄存器
要学指令首先要弄懂这些寄存器
8086/8088 CPU的寄存器共有14个,都是16位的寄存器,根据用途分为数据寄存器、段寄存器、地址寄存器和控制寄存器4种类型。
不过太多了,我挑几个重要的讲:
- 数据寄存器
数据寄存器包括EAX、EBX、ECX 、EDX四个通用寄存器,用于存放计算过程中所用的操作数、结果等信息,即是存放数据的寄存器。
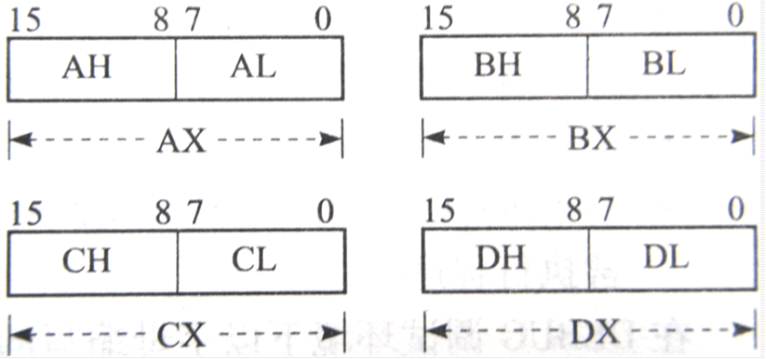
指针寄存器
这个就是指向的一些东西的寄存器
ESI:源变址寄存器,可用于存放源缓冲区的偏移地址。
EDI:目的变址寄存器,可用于存放目的缓冲区的偏移地址。
ESP:堆栈指针寄存器,用于指出堆栈区栈顶的偏移地址。
EBP:基址指针寄存器,用于指出堆栈区某个单元的偏移地址。控制寄存器
控制寄存器包括指令指针寄存器IP和标志寄存器FR,用来控制程序的执行。
指令指针寄存器IP(Instruction Pointer)
指出当前正在执行指令的下一条指令所在单元的偏移地址。标志寄存器FR(Flag Register)
标志寄存器FR共有有效标志位9个。下面这些了解就好了
状态标志:
C:最高位产生借位或进位标志。进位C=1
O:溢出标志。溢出O=1
Z:零标志。结果为0则Z=1
S:符号标志。就是结果的符号位。
P:奇偶标志。低8位中1的个数为偶数P=1
A:辅助进位标志。低半字节向高半字节有进位或借位,A=1
控制标志:
D:方向标志。D=1时串操作时自动减量
I:中断标志。I=1时允许CPU接收外部的中断请求
T:陷阱标志。T=1时进入单步调试状态。
指令部分
某些指令的差别就在会不会影响标志位或者会不会保存结果
关于有些不好记的指令
SHL(shift logical left): 逻辑左移
SAL (shift arithmetic left ):算术左移
SHR (shift logical right):逻辑右移
SAR (shift arithmetic right):算术右移
ROL (rotate left):循环左移
ROR (rotate right):循环右移
RCL (rotate left through carry):带进位循环左移
RCR (rotate right through carry) :带进位循环右移
影响标志位
add和lec
sub和dec
这两个是前者影响标志位,后者不影响
保存结果
test和add
cmp和sub
前者保存数据,后者不保存
寻址方式
是寻操作数的地址的方式
立即数寻址、寄存器寻址、存储器寻址
寄存器寻址:直接弄出来了寄存器中的数值,比如eax直接是指eax里面的数
存储器寻址:有直接、间接、基址
储存器寻址中:直接就是直接拿地址过来:[1000H]这种
间接: [eax] 也就是说要的不是eax中的值,要的是eax中这个表示了地址,再向内存中找这个地址
基址:[eax+1000H]这种,也就是把两种结合
关于汇编语言的条件判断
C语言条件跳转中a<b对应的汇编的汇编代码是
mov eax, [a];
cmp eax, [b]; //先比较a和b
jge XXX; //如果a>=b就跳到什么地方去
因为汇编和C语言好像是翻译上的不一样
在C语言中如果是a>b
那么在汇编语言中就是a<=b
顺便一说,这个跳转指令自己就是个条件跳转,根据的是标志位的变动
A>B:JG (JNLE)
A≥B:JGE (JNL)
A<B:JL (JNGE)
A≤B:JLE (JNG)
函数的形成和原理
函数的一些小知识
函数参数的传递顺序:
从右往左传递参数
不可以指令的两边都是要访问内存的变量
栈
栈在内存里面,并且这个数据的在地址中的顺序是从大到小这个方向在存储
从栈底到栈顶是逐渐变小的过程
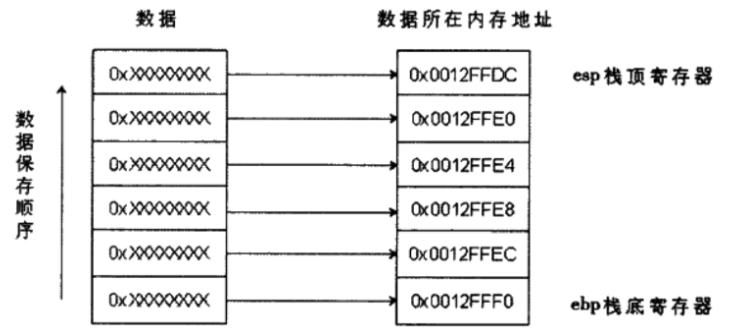
函数开辟栈的指令: push ebp ;
mov ebp,esp;
关闭栈的指令: mov esp,ebp;
pop ebp;
call指令:先把这个call指令的下一个指令入栈,然后再跳转到call指令这个指令的里面的那个指令里面
调用栈的步骤
- 开辟栈,注意每个栈的ebp都代表的是上一个栈的东西,有点像是在保存前任的东西
- 把栈的大小决定,然后再压入ebx,esi、edi
- 开始初始化栈,把栈里面全部的储存空间都变成一模一样的数字
- 把变量弄进栈,在edi的后面
- 当要调用函数的时候,call函数把eip的值入栈,放在edi后面(或者是在变量后面)
- 函数重新开一个栈,又是把main函数的ebp先存起来
- ret相当于 pop eip,把eip有弄回正道
- 最后栈平衡,目前来说就是有几个变量esp就往回加几个
栈平衡:
不同的两次函数调用,所形成的栈帧也不相同。当由一个函数进入到另一个函数中时,就会针对调用的函数开辟出其所需的栈空间,形成此函数的栈。
当这个函数结束调用时需要清除掉它所使用的栈空间,关闭栈帧,我们把这一过程称为栈平衡。
对于函数调用,有三种不同的调用方式
stdcall、cdecl、fastcall,这三个东西主要的区别在,是哪个部分实现的栈平衡

只有cdecl 可以弄不定参数的函数,并且也只有它是由调用方,也就是说是call那个函数的那边来平衡栈,其他的都是要函数这边来平衡
fastcall使用寄存器来传参
函数的返回值
函数的返回值一般是在寄存器eax上
 微信
微信 支付宝
支付宝