关于NLP的学习
深度学习的概念
深度学习从广义上来讲就是程序可以自己学习自己的意思。是指一个已经写好的代码程序经过大量的数据使得自身得到了发展
总共有三个部分的特征:
一、反向传播算法
二、特征提取能力
三、端到端之间的学习方法
学习pytorch
特点
中间有三个特点:
1、完全符合python编程(tensorflow就不行,是在python语法和TensorFlow自己有些格式之间转换)
2、方便的张量(tensor)计算 –>可以将变量加载到GPU(图形处理器)上
3、对动态计算图的支持 —->动态计算图,是pytorch的特有特性,是可以用来表示反向传播算法的一种图示
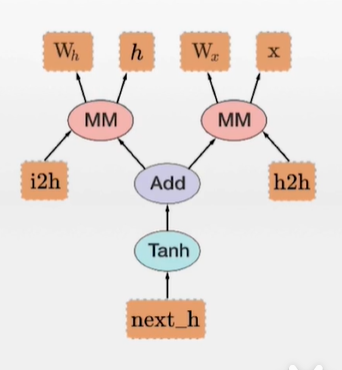
使用pytorch进行深度学习的步骤
构建神经网络模型
1 | neu = torch.nn.Sequential( |
这个格式的参数输入可以将所有神经网络的参数储存在neu.parameters中
其中输入层的每一个神经元都是多维向量的一个维度
建立损失函数和优化器
损失函数
用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的模型用的损失函数一般也不一样。
pytorch中的损失函数
1 | cost = torch.nn.MSELoss() |
torch.nn.MSELoss() <——–> torch.mean((y-y*)^2)
意识是预测值和真实值差的平方的平均值
cost是函数指针,指向这个mseloss函数
优化器
1 | optimizer = torch.optim.SGD(neu.parameters(),lr=0.01) |
neu.parameters是定义好的神经网络中的所有等待被优化的所有参数的集合
lr是学习效率参数
对神经网络进行分批次训练
预处理
数据预处理
类型变量:数值的大小没有特殊的含义。比如说预测当地此时具有的共享单车数的时候的”星期几”这个变量。与之相对的是–特征变量(特征属性,在一个表中的特征列)
预处理手段
一、对类型变量进行类型编码,比如one-hot编码
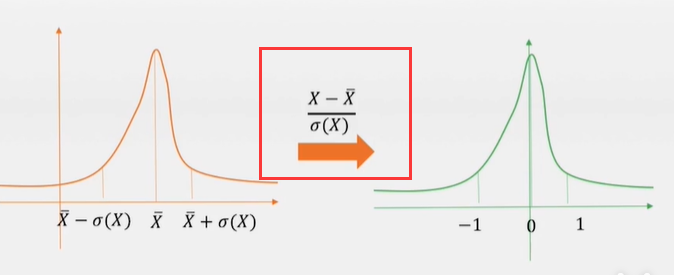
二、数据变量标准化(归一化),对数值变量进行统一化运算,使其更加方便运算。(比如对数据减去均值再除以方差)
三、分批训练,将其分类为训练集、测试集。还有将其切分成小批,一批一批地进入神经网络,每一批训练网络一次
实例:关于分类相关的深度学习
例子:文本分类的问题
文本向量化
文本向量化是将一个不固定长度的文本变成一个固定长度的向量
所采用的技术就是词袋模型
词袋模型是指将一段文本的所有词视为一个装满文本的大袋子,忽略单词之间的顺序,只看频率,并且将这个大袋子中的单词全部变成向量,有多少个单词就是多少维的向量
举例:
1 | 我 爱 北京 天安门 |
那么我们对应的单词表就是
{我,爱,北京,天安门,每个,人,都有,一个,的}—–> 九维向量
1 | 我 爱 北京 天安门 |
构造分类器
1 | model = nn.Sequential( |
pytorch的工具
TensorBoard的使用
TensorBoard是一个对于我们想要展示的图片的展示平台
在存在pytorch的环境里面的终端使用命令
1 | tensorboard --logdir logs(这个是你规定的文件夹名) --port 你的端口 |

语法
首先需要导入包
1 | from torch.utils.tensorboard import SummaryWriter |
对SummaryWriter生成对象,使用PIL来将路径中的图片来变成对象
1 | writer = SummaryWriter('logs') |
使用numpy把PIL的对象变成numpy的数组,再导入进Writer对象,(writer中只接受numpy数组或者其他的参数,反正PIL的不行)
1 | img_array = np.array(image_PIL) |

或者我如果想要添加数组,做图像
1 | for i in range(100): |
最后关闭函数
1 | writer.close() |
transform使用
transform是pytorch中的一个工具箱,里面有很多的功能工具
一般来说是用来对图片做一些处理,输入一个图片,输出一个结果
用法(以totensor()为例)
首先弄一个对象,transform的对象,再输入一个图片类型 就可以对其操作,进行输出
1 | from torch.utils.tensorboard import SummaryWriter |
还有很多其他的,compose()主要是合并,resize()是改变图片大小
就懒得讲了
pytorch数据集的读取
torchvision中的datasets和DataLoader
这是一个图片的数据集的模块,有关图片的数据的读取利用都是用这个模块
dataset用法
1 | import torchvision |
DataLoader用法
1 | test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, drop_last=False) |
 微信
微信 支付宝
支付宝